PI 3: This isn’t a Secure Line
Description:
Our suspect is getting noided. We’ve managed to retrieve this from his computer. What can you find?
The flag format is the MD5 hash of what you will find. rgbCTF{hash}
Category: Forensics
First Blood: 9 hour, 16 minutes after release by team RedRocket
To try out this challenge, download the file here
The other questions in this series: PI1 and PI2
The Solution
Checking the file type with file data reveals that it is yet another BTSnoop file. After investigating in wireshark, we can tell that this is some kind of audio device that is both transmitting and receiving audio data. How do we know this?
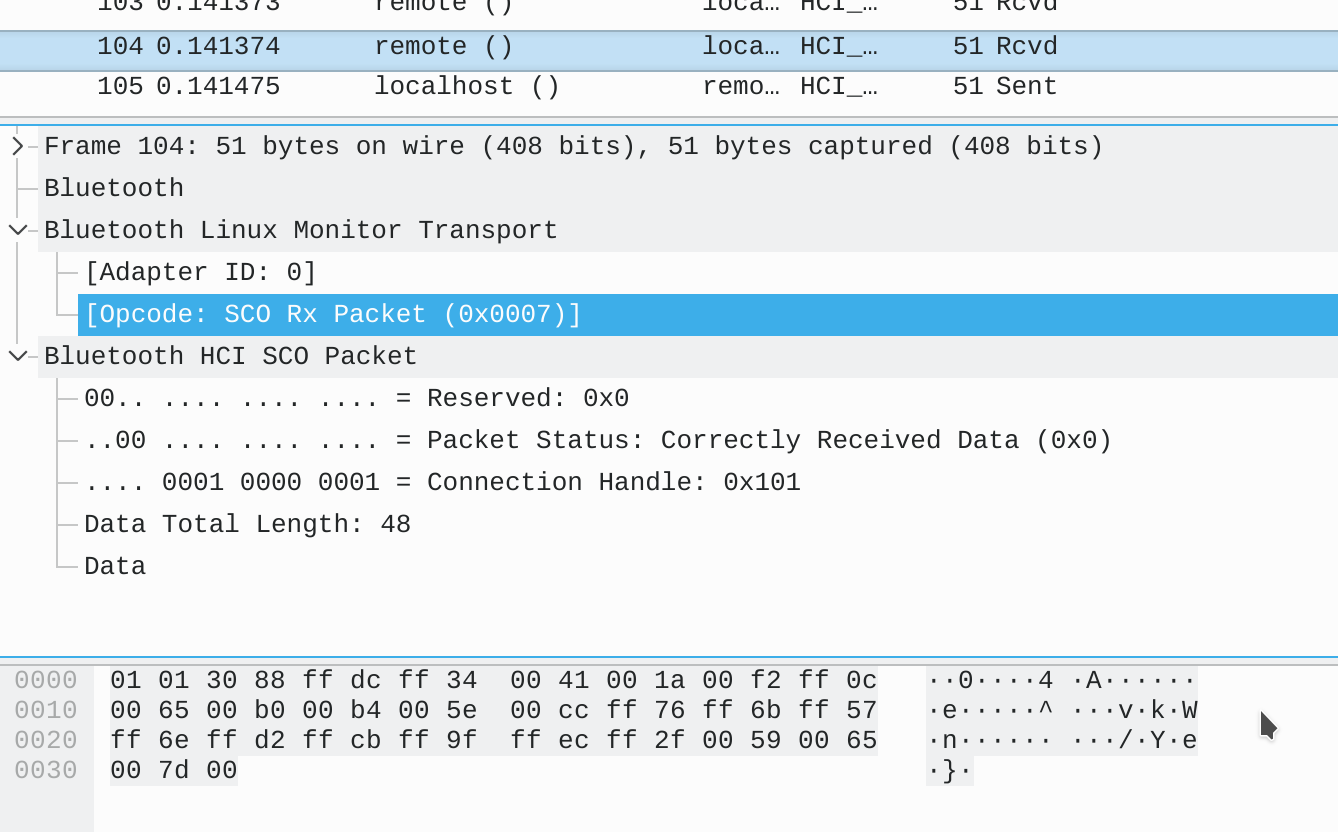
From [Opcode: SCO Rx Packet (0x0007)], we know this is SCO data being received
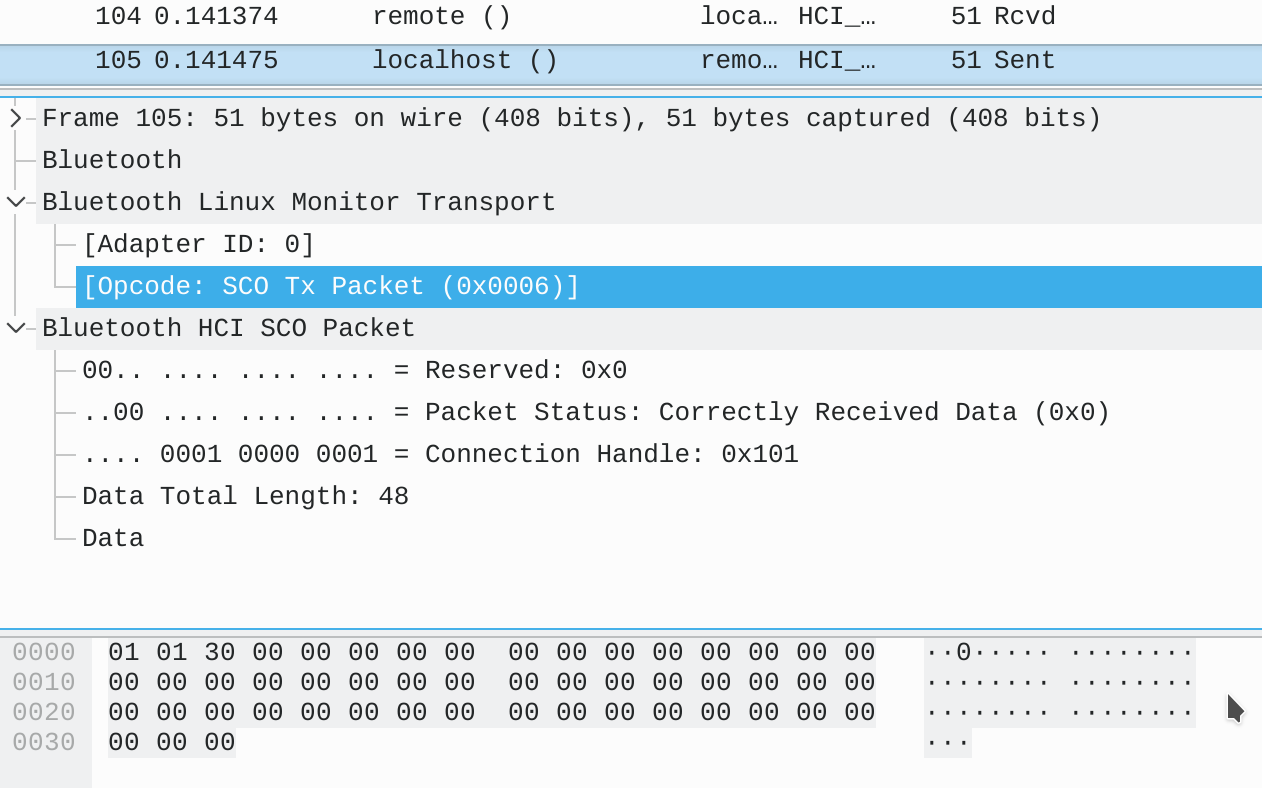
And from [Opcode: SCO Tx Packet (0x0006)], we know that this SCO data is being transmitted
Googling bluetooth SCO reveals that it is a blueooth audio protocol used commonly in bluetooth Headset Profile and Intercom Profile. It can’t be Intercom Profile because we know that this data was captured from a computer, so it must be Bluetooth Headset Profile. That means that it is audio data, and even better, we know it is likely a phone call.
So, how do we listen to this audio data?
Jerry-rig method
Upon exporting this packet capture in JSON, it appears that the data is not preserved. Lets just rip it out of the capture file in python. How many problems in history I wonder have been solved by opening a wee IPython terminal?
We know that each SCO packet contains 48 bytes of audio data preceeded by 01 01 30, so lets split on b"\x01\x01\x30" and see what happens.
In [1]: with open("data", "rb") as rp:
...: data = rp.read()
...:
In [2]: data.split(b"\x01\x01\x30")[3]
Out[2]: b'\xce\x01\x86\xff\x8e\xfbt\xfd\x10\x02X\x03o\x02*\x00\xc3\xfd{\xff\xa6\x02\xbb\x00\xc1\xfc\xec\xfb$\x02\x8d\x06\xfe\xffs\xf7\x0c\xf7\t\x03y\r\xdb\x08\x99\xfa\xf1\xf4\x00\x00\x003\x00\x00\x003\x00\x00\x00\x06\x00\x00\x00\x00\x00\xe2\x87i|d\r\x0b'If we compare the above output (which is the fourth element of that split), to the third packet in wireshark, we see that the data part is the same. Great. However, further analysis (mucking about in IPython) reveals that some information for the next packet is attached to the end of our audio data. Luckily, as stated above we also know that the audio data is 48 bytes, so lets split our output and see where it gets us
In [10]: [(x[:48], x[48:]) for x in data.split(b"\x01\x01\x30")][3]
Out[10]:
(b'\xce\x01\x86\xff\x8e\xfbt\xfd\x10\x02X\x03o\x02*\x00\xc3\xfd{\xff\xa6\x02\xbb\x00\xc1\xfc\xec\xfb$\x02\x8d\x06\xfe\xffs\xf7\x0c\xf7\t\x03y\r\xdb\x08\x99\xfa\xf1\xf4',
b'\x00\x00\x003\x00\x00\x003\x00\x00\x00\x06\x00\x00\x00\x00\x00\xe2\x87i|d\r\x0b')Still with me here? We’ve split this data into what we definitely know is audio (the first 48 bytes) and the header for the next packet, which as you can see, contains the aformentioned opcode value:
b'\x00\x00\x003\x00\x00\x003\x00\x00 -> \x00\x06 <- \x00\x00\x00\x00\x00\xe2\x87i|d\r\x0b'
And we discover it is 24 bytes so the next step is to search the previous 24 bytes of each occurence of b"\x01\x01\x30" for the opcode and couple it with the 48 bytes of audio data that comes after.
In [20]: Rx = []
...: Tx = []
...:
...: #Get the index of every occurence of b"\x01\x01\x30"
...: for m in re.finditer(b"\x01\x01\x30", data):
...:
...: ind = m.start()
...:
...: # Get the 24 bytes of data that comes before the SCO audio data
...: meta = data[ind-24:ind]
...:
...: # Get the raw audio from the SCO packet
...: audio = data[ind+3:ind+51]
...:
...: if b"\x00\x06" in meta:
...: Tx.append(audio)
...: elif b"\x00\x07" in meta:
...: Rx.append(audio)
...:
In [21]: len(Rx)
Out[21]: 13480
In [22]: len(Tx)
Out[22]: 13480As you can see, we have harvested the same amount of Rx and Tx packets, which is a good sign. Finally, we write the raw audio data to a file from IPython
In [68]: with open("Rx.raw", "wb") as wp:
...: wp.write(b"".join(Rx))
...:
...: with open("Tx.raw", "wb") as wp:
...: wp.write(b"".join(Tx))
...: The final challenge is getting this audio to open and play correctly. The documentation is scant for this kind of thing but there are a few sources online that I found. namely this post and this paper (see section 6.3 and 6.3.1).
Bluetooth SCO audio is a mono audio signal with signed 16-bit PCM at 8000 Hz. You can either import this in Audacity File -> Import -> Raw Audio or play it straight from the terminal with sox
$ play -c 1 -t s16 -r 8000 Tx.raw
play WARN alsa: cant encode 0-bit Unknown or not applicable
Rx.raw:
File Size: 647k Bit Rate: 128k
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 8000Hz
Replaygain: off
Duration: 00:00:40.44
In:100% 00:00:40.44 [00:00:00.00] Out:324k [ | ] Clip:0
Done.The Rx audio is data received by the device we are capturing packets on, Tx is data being transmitted to the bluetooth headset.
I have merged and converted both Rx and Tx to an mp3, so you can listen in on the phone call in your browser, see here
Listening to the audio file we can discern that our suspect is “changing the password” to applepie. So we take an MD5 hash of applepie for the flag: rgbCTF{6cc7c5a5a21978e5587a59186cadb5e3}
The above IPython scripts have been compiled into a script file below:
import sys
import re
data = b""
print("python3 sco2audio.py BTSNOOP_FILE")
with open(sys.argv[-1], "rb") as rp:
data = rp.read()
Rx = []
Tx = []
#Get the index of every occurence of b"\x01\x01\x30"
for m in re.finditer(b"\x01\x01\x30", data):
ind = m.start()
# Get the 24 bytes of data that comes before the SCO audio data
meta = data[ind-24:ind]
# Get the raw audio from the SCO packet
audio = data[ind+3:ind+51]
if b"\x00\x06" in meta:
Tx.append(audio)
elif b"\x00\x07" in meta:
Rx.append(audio)
with open("Rx.raw", "wb") as wp:
wp.write(b"".join(Rx))
with open("Tx.raw", "wb") as wp:
wp.write(b"".join(Tx))
print("\nEITHER import into audacity as raw data -> MONO -> 16-bit signed -> 8000Hz")
print("OR install sox and do:\n\tplay -c 1 -t s16 -r 8000 FILE.raw\n")Clean method
Shoutout to lukas2511 of RedRocket for this method, which is lifted from his solution.
Lukas’s method is far less barbaric and first relies upon converting the BTsnoop file to a pcap, then simply using pythons pcap library scapy to process through it. The reason I shout this out is that I did not think to (or know one could) do this and have subsequently learnt something useful. Cheers Lukas!
#!/usr/bin/env python3
import scapy.all as scapy
rcvd = b''
sent = b''
for pkt in scapy.rdpcap("data.pcap"):
pkt = bytes(pkt)
if pkt.startswith(bytes.fromhex('00000007')):
rcvd += pkt[7:]
elif pkt.startswith(bytes.fromhex('00000006')):
sent += pkt[7:]
open("rcvd.raw", "wb").write(rcvd)
open("sent.raw", "wb").write(sent)